# BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.MLA
Bidirectional Encoder Representations from Transformers.
# 跟之前工作的区别(GPT、ELMo)
- 跟GPT的区别是,gpt考虑的是单向的,用左边的信息预测未来的信息;而bert为双向的架构,用了左侧和右侧的信息,提升某些任务的性能,提出了MLM
- 跟ELMo的区别是,elmo是RNN的架构,面对下游任务需要做调整;而bert是transformer架构,比较简单,只需要改最上层就行
综合一下,RNN只有双向,但是架构差,GPT模型结构好,但是单向,因此BERT将这两点进行结合,得到了双向的Transformer结构
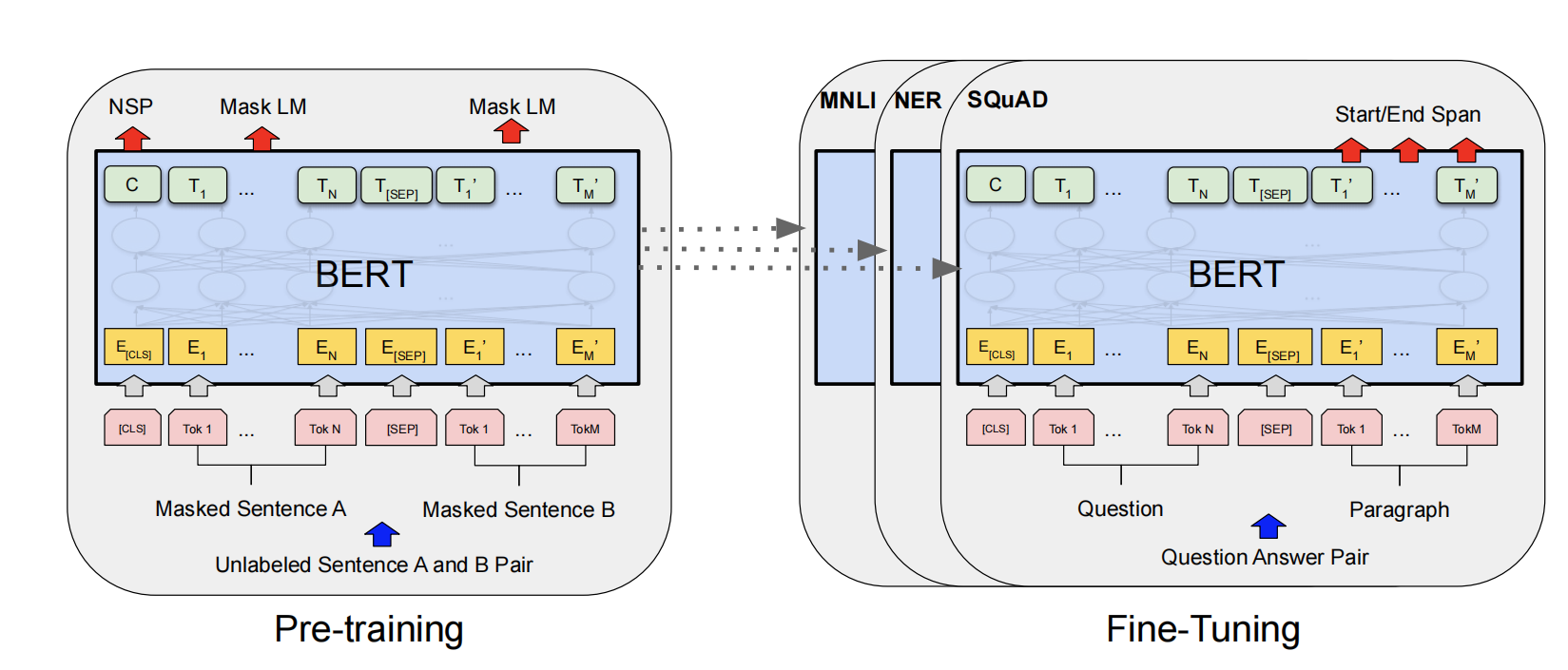
# INPUT

图2. bert的输入embedding
相比Transformer,调了三个参数
- Base:层数是L=12,维度H是768,head A是12;因此总共参数为1亿
- Large:层数是L=24,宽度H是1024,head A是16;总共参数3.4亿
- 因为有些任务比如QA是看句子的关系,因此需要句子对(Sequence),这里不一定是严格的句子,可能是一个文本块,因此文中称为sequence;Transformer的输入是一个句子对,因为编码器和解码器都需要输入对应句子
- 采用了WordPiece embedding。传统方法用空格作分割单词,但如果语料很大的话,导致词典特别大,如果这个很大,就导致模型整个可学习参数都在embedding层上了;wordpiece是说如果某些词出现的概率不大的话,应该将其切开,看子序列,如果其中有词根,并且词根出现概率很大,那就只保留词根,最终3w
- 每个句子开头是[cls],作为句子的表征,因为attention机制可以保证看到句子中的每个词,因此放在开头是ok的,另外在两个句子间放一个[sep]来区分不同句子输入,使用token type做了一个embedding
最终Embedding为 token embedding + segment embedding + position embedding
# Pre-training
(无标号的数据)
# Task1: MLM(Mask Language Model)
- 随机选择15%的词[MASK]掉
- 随机选择80%的词替换成其他词
- 随机选10%什么都不做
# Task2: NSP (Next Sentence Predict)
预测上个句子是否是下个句子
# Finetune
(有标签的数据)
根据下游任务设计输入和输出,原始作者建议2-4个epoch,但是实验证明太少了,方差太大不稳定,有人建议20个epochs:*Mosbach et al even recommend fine-tunig for 20 epochs,*而且作者实验时采用的是Adam的不完全版,需要用Adam的正常版
作者用了预训练的输入做任务,跟微调的结果比差很多,因此作者建议微调使用